Bash 学习小计(二)
很多看似复杂的系统背后实现其实真的很复杂,是因为它过多地使用了胶水语言和指令语言承载业务逻辑。这篇文章记录的是最近在使用 shell 时候学习到的一些小技巧和我认为适用与一定业务场景的比较好的实践。
字符串处理
Shell 有很多命令语句如 awk,sed 都可以做字符串各种操作,其实 Shell 还内置有一系列操作符号,可以达到类似效果,使用内部操作符会省略启动外部程序等时间,因此速度会非常的快。
举个例子,要把用户输入的一段带路径的文件名把文件路径和文件名分离开来可以使用如下操作符:
FILE_PATH=AAA/BBB/target/demo.jar
${FILE_PATH%/*} # output: AAA/BBB/target/
${FILE_PATH##*/} # output: mode.jar
获取一个变量展开后的值:
echo $PARAM_KEY="${!PARAM_KEY}" > file
再例如,替换一个变量中指定的值:
TIMESTAMP=`date +%H:%M:%S`
TARGET='now is ${TIMESTAMP}'
TARGET=${TARGET//\$\{TIMESTAMP\}/$TIMESTAMP} # now is 21:05:57
类似的语法可以用于截取、替换、连接、获取长度、获取位置,更详细的操作说明可以参考这篇博客:https://www.iteye.com/blog/justcoding-1963463。
使用 Python 作为 Bash 命令
有时候想要在 Shell 中使用一些简单的命令碰巧是某个 Python 库提供的,这个时候可以考虑把 Python 代码作为一个 Bash 命令,只需要一个 Alias,当然还要求你的操作系统环境中装有对应版本的 Python,例如 url encode & decode:
alias urldecode='python -c "import sys, urllib as ul; print ul.unquote_plus(sys.argv[1])"'
alias urlencode='python -c "import sys, urllib as ul; print ul.quote_plus(sys.argv[1])"'
# 使用
urlencode "中文" # %E4%B8%AD%E6%96%87
urldecode "%E4%B8%AD%E6%96%87" # 中文
文件标识符
Shell 输出重定向有几种管用用法,比如把 输出重定向到文件:command >file,把错误输出重定向到标准输出:command 2>&1,但当两种命令连起来使用的时候容易误写为command 2>&1 >file ,这种情况下错误输出并不会打印到文件而会一直占用标准输出打印到控制台,因为 Bash 是顺序执行的,2>&1 把 sterr 重定向到了 stout,>file 又把 stout 重定向到了 file,可这个时候 sterr 还在 stout,如下图所示,
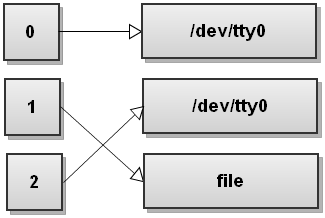
这种情况可能在导致后台进程无法按预期退出到后台,正确的写法应该是:
command >file 2>&1
# 或者
command &>file
这里有篇文章对 Bash 文件表示符重定向做了详细的解释:http://kodango.com/bash-one-liners-explained-part-three,同一个系列的文章翻译质量和内容都很扎实,推荐有时间的朋友读一读。
逐行读取
对于标准输出逐行处理的需求,可以使用 IFS(Internal Field Seprator,内部域分隔符)按行读取,再使用 read 命令写入变量中处理,例如对于不同字符开头的日志上色:
step_exec() {
$@ 2>&1 | while IFS= read -r line; do
if [[ ${line} = \+* ]]; then
echo -e "\033[1;36m[`date +%H:%M:%S`] [执行命令] $line";
elif [[ ${line} = \[ERROR\]* ]]; then
echo -e "\u001b[91m[`date +%H:%M:%S`] $line";
elif [[ ${line} = \[WARNING\]* ]]; then
echo -e "\u001b[33m[`date +%H:%M:%S`] $line";
elif [[ ${line} = \[SUCCESS\]* ]]; then
echo -e "\u001b[92m[`date +%H:%M:%S`] $line";
else
echo "[`date +%H:%M:%S`] $line";
fi
done
return ${PIPESTATUS[0]}
}
export -f step_exec >>/dev/null
除了日志处理还可以用 $PIPESTATUS 变量获取管道符中第一个管道内的退出码。
export -f 是模仿 js 的写法,把一个方法归置到一个文件中,用 export + source 的方式被其他文件应用。
请求重试
对于 curl 命令请求充实的需求,有如下实现:
retry_times=0
while
curl --fail $URL
[[ $? != '0' ]] && (( retry_times < 3 ))
do
echo RETRY... $retry_times
(( retry_times++ ));
done
首先 curl –fail 可以让 curl 在得到返回码非 200 的时候以 22 为退出码错误退出,这个时候可以把重试次数和退出码作为判断条件作为是否重试的标示。bash 没有 do-while 语法,示例中是一种用 while-do 达到 do-while 效果的写法。
另外 bash 中书数学运算推荐使用 (()) ,双括号的语法比传统的 expr /let更简洁高效,且 shell 原生支持而不需要内置命令工具。
条件判断语句
bash 条件判断的坑集中在变量是否展开上,例如 ls 的文件名称是否带空格,条件表达式中的变量展开是否带有空格或者特殊字符等等,使用 [[]] 双括号可以有效地避免这种问题,所以任何情况下条件判断语句中都推荐优先使用双中括号。
另外一个很实用的判断文件中是否包含某字符串的写法:
if grep -q 'Connection timed out\|The remote end hung up' $WORK_SPACE/error; then
return 1 # 超时重试
fi
利用 grep -q没有找到匹配就非零退出的特性,不仅比 $(grep ... ) != …这种写法更优雅,还可以避免多个子进程带来的问题。