Lambda初体验
使用Lambda和CloudTrail给新创建的bucket打上tag
背景介绍
什么是Lambda
AWS Lambda提供了一个不需要服务器就能运行代码的平台,有以下特点:
- 高伸缩:适用于一天数次的访问频率到一秒数千次的访问量,横向纵向灵活扩展
- 按需付费:你只需要根据访问量付费,价格非常便宜($0.20每百万次访问)
- 高可用:AWS负责维护代码运行的环境,使用者无需操心底层资源的配置,性能,维护
- 支持语言:目前官方支持NodeJS, java, C#, Python, 有第三方工具可以支持多种语言
- 事件响应:Function是Lambda的计算单元,可以由各种事件触发,这个事件可以是由AWS内部的资源发出的,也可以来自AWS外部。(比如往S3存放一个文件,或者一个HTTP请求)
使用场景:
- 构建一个数据触发的程序用于处理数据,处理Amazon Kinesis中存储的流数据
- 构建一个微服务后端的一个模块,配合API Gateway用于响应HTTP事件
什么是CloudTrail
用于记录和追踪AWS内部的各种API调用,你可以在CloudTrail的日志中找到所有该账户在AWS中操作资源的事件,包括Console操作,SDK,AWS CLI,以及跟高级服务的调用。
你可以在事件中找到资源调用者的用户信息,源IP,以及调用时间。
使用Lambda和CloudTrail实现创建一个S3 bucket自动打上创建者的tag
CouldTrail 会把所有监控到的API调用的时间写到S3 bucket里的日志文件中,同时产生一个event时间,我们要做的就是用这个event事件触发一个Lambda function,调用AWS的SDK获取API调用日志,当发现日志里出现了CreateBucket事件的时候,给这个bucket打上形如“Owner:dyd”的tag。

非常类似于这个功能不过最后吧SNS换成了打tag。
- AWS CloudTrail把日志保存在S3中
- S3 发出一个
s3:ObjectCreated:*的事件触发了Lambda function,这个配置在Lambda中实现 - Lambda使用你创建function时赋予的role来执行function
- Lambda获取S3的事件作为一个参数,确定CloudTrail的日志存放在S3中的位置,进而读取日志,当日志中出现eventName=CreateBucket的事件的时候,获取该事件对应的BucketName和UserName,调用AWS S3 SDK
- 使用S3 SDK给对应的bucket打上包含UserName的tag
Step by Step
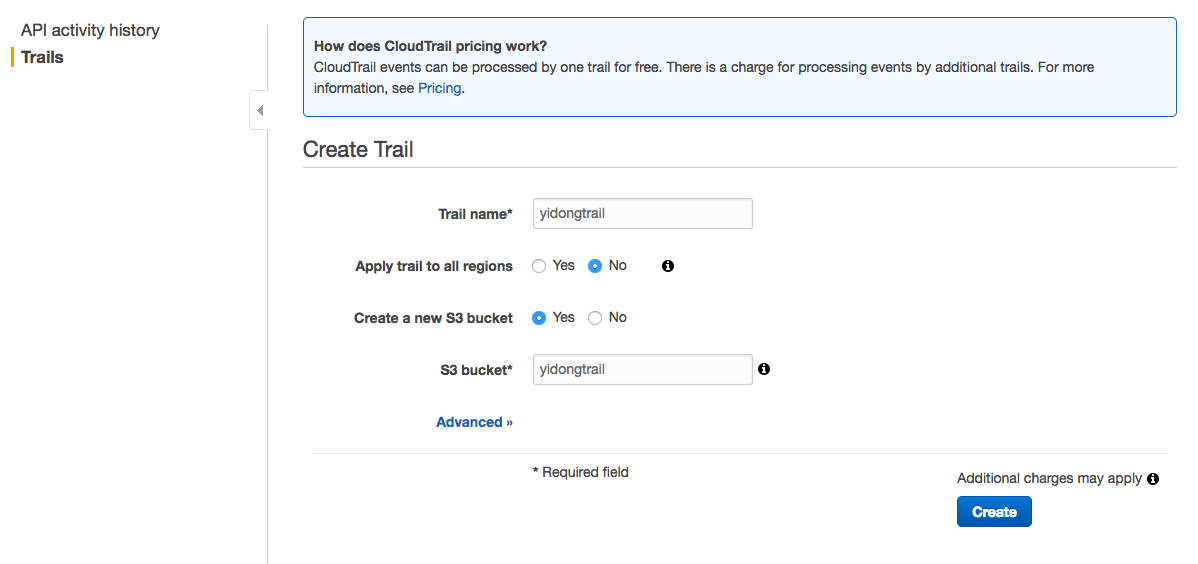
第一步,创建一个Trail
首先你得有一个AWS账号,选择一个Region,进入CloudTrail的界面。
选择左侧Trail -> Add new Tail,填写如下信息
Trail Name: Trail的名字,只需要不于同Region的CloudTrail重名即可
Apply trail to all regions: 是否需要在所有Region都使用这个CloudTrail,否则只监听CloudTrail所在Region的API调用事件。
S3 bucket: 用于存放CloudTrail日志
填选好后点选Create
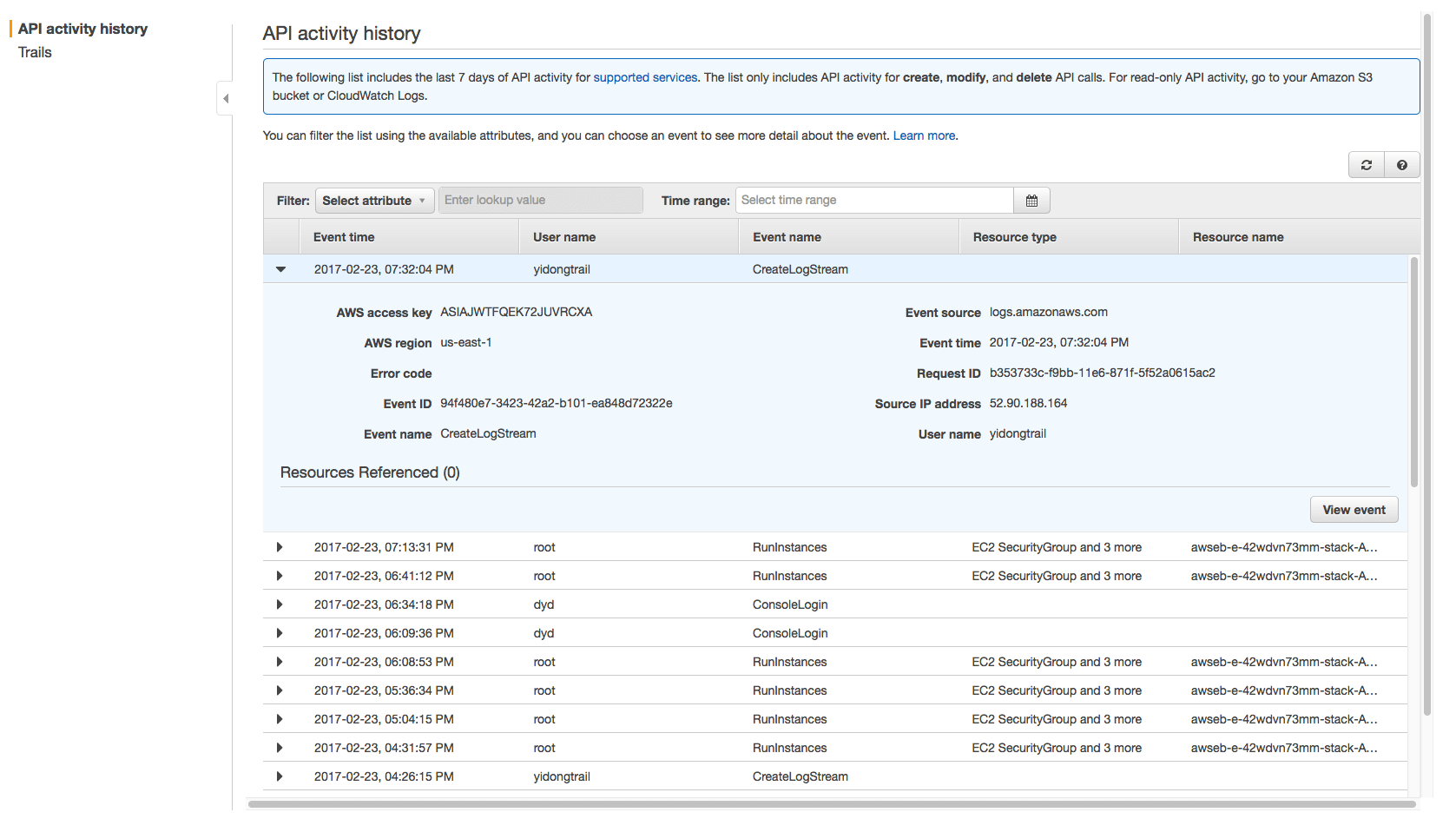
点击新创建的Trail你可以进行配置,确认右上角log为打开状态。
过一会儿你就可以在API activity history里看到如下所示的一些event事件了,主要包含事件触发的用户名,时间名称,类型,资源名称。
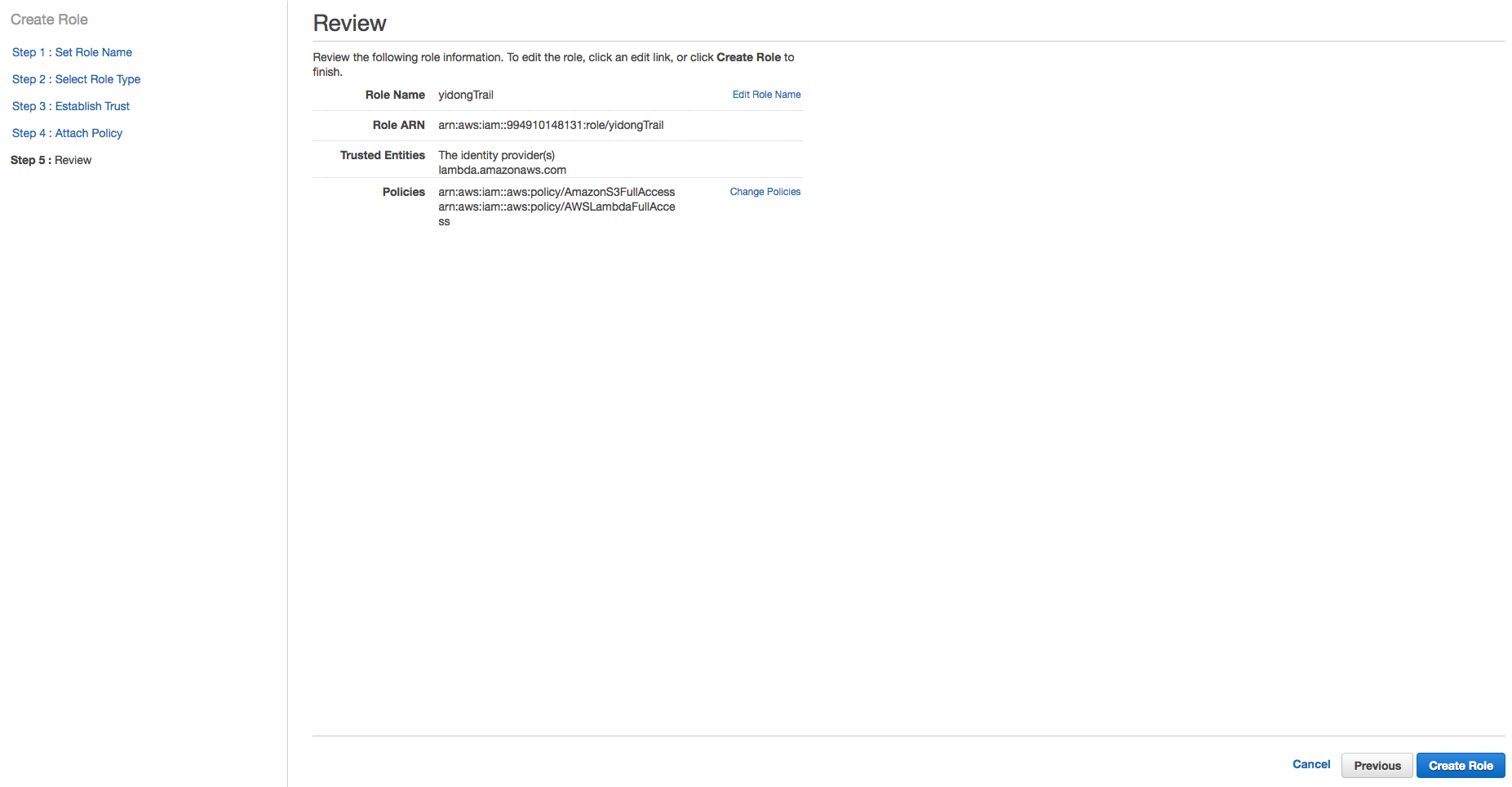
第二步:为Lmabda function创建一个role
进入 IAM -> Roles, 点击 Create New Role,输入Role的名字,点选下一步:
选择 AWS Lambda,下一步:绑定一个Polly
这里因为我们除了读取S3的object还需要给S3的bucket打tag的权限,所以方便起见选择AmazonS3FullAccess,另外这个Role需要执行Lambda的权限,所以还需要选择AWSLambdaFullAccess,最后,确认 -> 创建
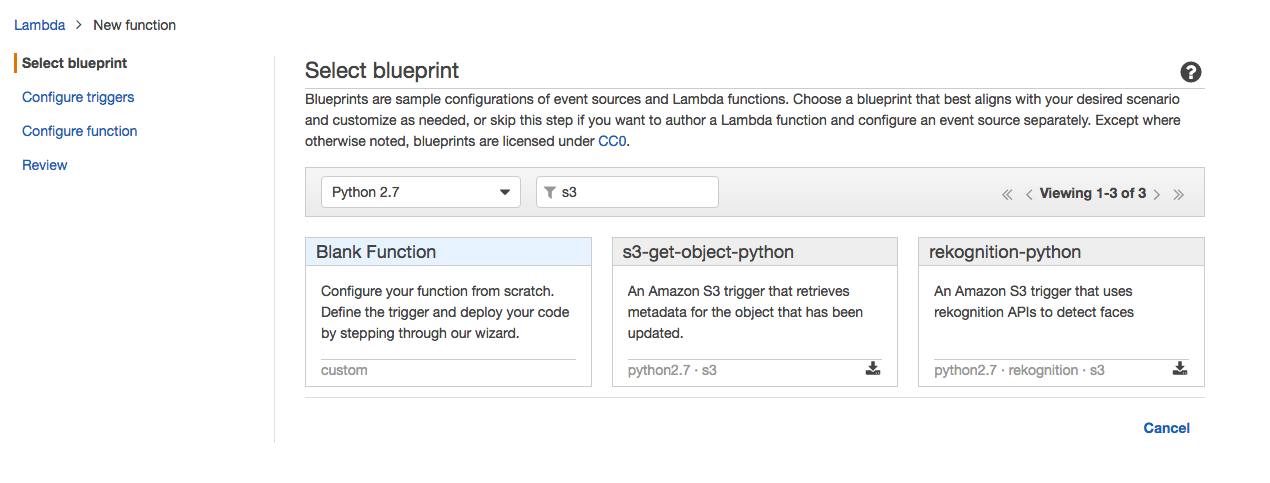
第三步:创建Lambda function
进入Lambda的界面点选Create a Lambda function
在Select blueprint的页面选择python2.7的运行环境,选择s3-get-object-python作为预配置
Configure Triggers 页面选择存放CouldTrail日志的S3 Bucket, 事件类型选 Object Created,勾选上Enable Trigger。
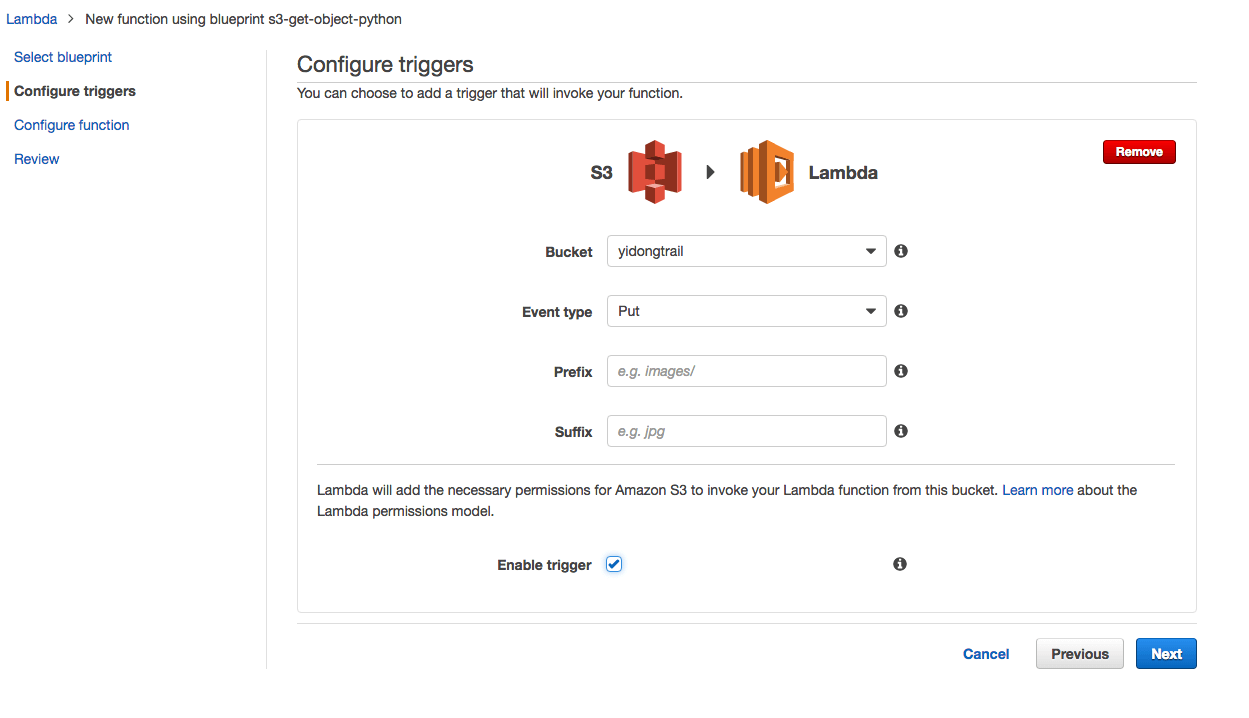
点击Next,输入Name,选择Role Name为上一步创建的Role,其他保持默认,Next -> 确认配置 -> Create function
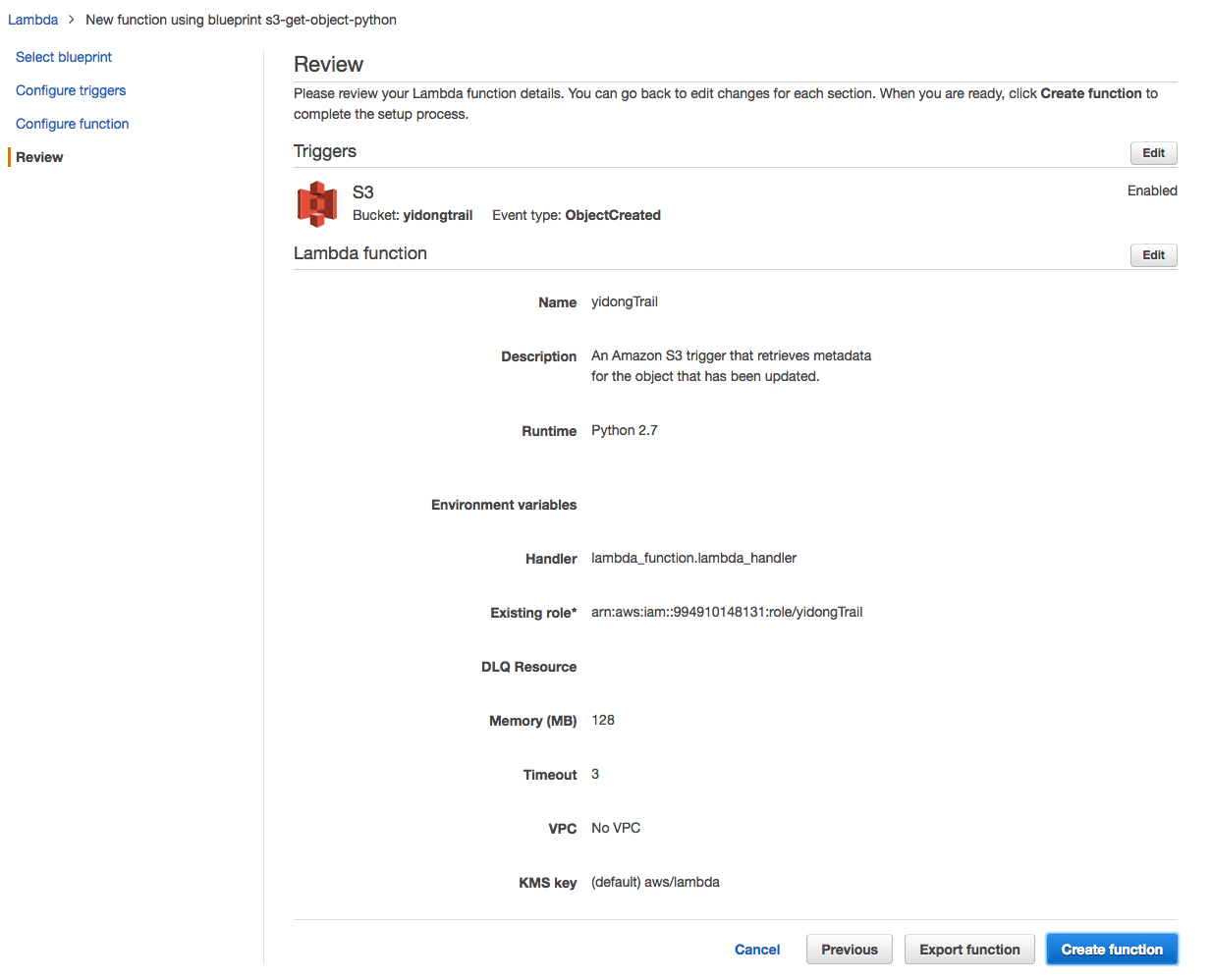
这里关于Lambda的部署方式,在生产中一般使用打包上传的方式,这里我们的案例比较简单,就直接在consloe上编辑了。
第四步: 获取测试数据
首先你需要测试你的Function能够被正常Trigger并拿到测试数据,所以你需要取消注释掉lambda_hander里面的第一行:
print("Received event: " + json.dumps(event, indent=2))
余下的不用管,点击test,你可以在Log output中看到你的测试内容,即event事件,即可。
接下来你需要取得一份样本数据用于测试,最简单的方法就是创建一个S3 bucket,这里一定要注意,创建的bucket需要和CloudTrail在同一个Region,否则事件是无法被捕获的。
进入S3 -> Create bucket 快速创建一个Bucket:
稍等数分钟,这里会有十几分钟的延迟,在Cloudwatch中查看Lambda打印的log:
进入Cloudwatch -> Logs -> 对应Lambda名称的Log Group -> 找到时间点对应的Log Stream,filter你的bucket名字你会发现一条这样的Log:
{
"Records": [
{
"eventVersion": "2.0",
"eventTime": "2017-02-23T13:42:18.654Z",
"requestParameters": {
"sourceIPAddress": "54.224.144.182"
},
"s3": {
"configurationId": "fa401b72-97f2-48e8-9b74-b8d2a726a771",
"object": {
"eTag": "25c76ac2f0284796baacebca934c3875",
"sequencer": "0058AEE6BA925A5848",
"key": "AWSLogs/994910148131/CloudTrail/us-east-1/2017/02/23/994910148131_CloudTrail_us-east-1_20170223T1340Z_nIJHY6wtS6EQRUtz.json.gz",
"size": 17181
},
"bucket": {
"arn": "arn:aws:s3:::yidongtrail",
"name": "yidongtrail",
"ownerIdentity": {
"principalId": "A1EKSBYVFNIFR0"
}
},
"s3SchemaVersion": "1.0"
},
"responseElements": {
"x-amz-id-2": "jN1tHU9s2/Y1RvA31IG34MhbHiAtB/45v938qdzsff2ufgZ8v5osNCcPKNWVrlnuh4qTs/J0odg=",
"x-amz-request-id": "57FBF80C150FB0CE"
},
"awsRegion": "us-east-1",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "AWS:AROAI6ZMWVXR3IZ6MKNSW:i-012030f0061c32dcd"
},
"eventSource": "aws:s3"
}
]
}
这就是我们要的测试数据
编写Function函数
把上一步得到的json文件放到Lambda的“单元测试”(我是这么理解的)里:
选中你的Function -> Actions -> Configure test event,直接把这个json粘贴进去。
下面你可以一边写代码一边运行测试。
我得说AWS console的这个工具确实不太好用,推荐自行谷歌好用的第三方工具做这个事。我是在本地进行测试和断点调试的。
写好的代码在这里,可以作为参考:https://github.com/ADU-21/test_lambda/blob/master/lambda.py
保存测试通过之后,你可以再尝试创建一个bucket,这个bucket在创建完成后十几分钟会被自动打上一个tag.
总结
Tag作为AWS官方推荐的管理资源计费的方式却并没有提供相应的接口给每个用户创建的资源打上自己的tag,我做这个实验的初衷原本是想通过这种方式给所有的AWS资源都打上tag,但是在操作过程中发现CloudTrail的日志并没有想象中那么容易过滤出有用信息,比如Create Instance这个动作并不会只有一个CreateInstance的event时间被产生,而是会在长达数十分钟的时间里产生多个RunInsatance的事件,时间延迟也是一个不小的问题,关于资源管理,还需要探索更好的方案。