AWS认为,什么样的架构是一个良好的架构
AWS Well Architected framework,其实是亚马逊的一封白皮书,围绕云架构设计的安全性,可靠性,负载,花销,运维(2016年11月加入)五个支柱阐述了一个良好的架构应该遵循什么样的原则,以及一些最佳实践。
亚马逊在云服务届处于世界领先水平,且在十多年的云架构实践中已经积累了相当的经验,该白皮书是对这些经验的一个总结和提炼。不管是对于考试,对于成为一个云架构师,还是对于单纯的学习和了解云服务,都是一份不可多得的好材料。
下面附上资源地址:https://d0.awsstatic.com/whitepapers/architecture/AWS_Well-Architected_Framework.pdf
啰嗦几句
自从互联网诞生以来,各互联网公司通过将自己服务器的端口暴露在公共网络的方式提供服务,普通用户通过供应商接入公共网络,与公司服务器建立连接进行数据传输,从而实现“上网”的功能。对普通用户而言,终端以外的世界都是黑盒,而对于提供服务的互联网公司而言,则要运维大量的服务器,交换机等设备,为了保证服务的可靠性,容灾能力,为了开发,测试,常常需要维护超过实际提供服务的服务器数量很多倍的基础设施。又例如,在淘宝双十一期间可能由于用户访问量基层淘宝需要临时增加一倍的服务器数量来保证服务的正常运行,而在活动结束后,又需要恢复正常的服务器数量,那么这多出来的一倍服务器难免就会造成资源浪费。而且在很多时候,传统运维的背景下,申请一台服务器时间很长,手续繁琐,为了方便,研发部门通常会申请超出所需的基础设施资源,“以备不时之需”,这样的情况也会给企业造成大量的浪费。云服务,就是为了解决这种种问题而诞生的。
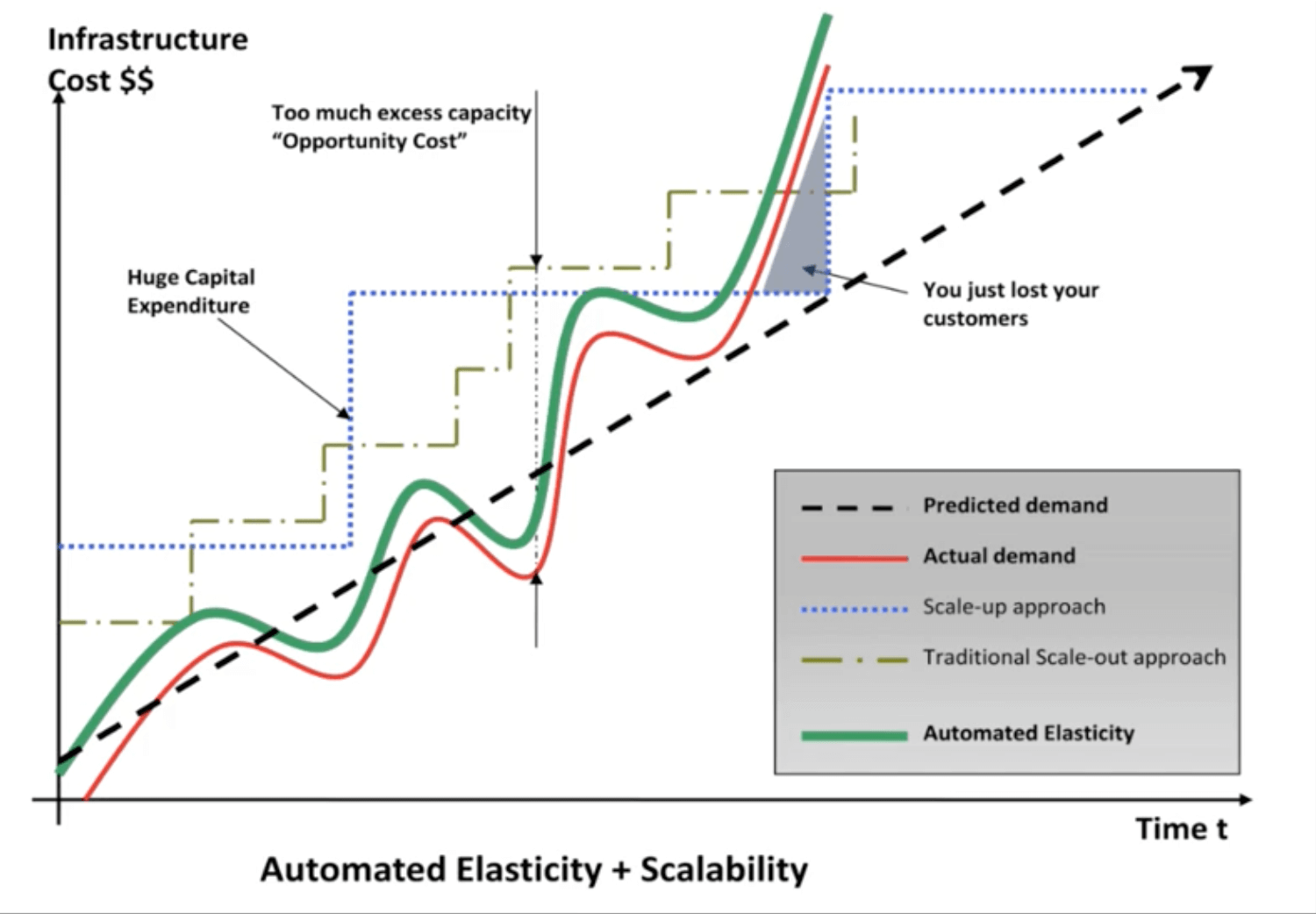
最简单的云服务模型,就是在云服务厂商集中托管了一个超级大型的服务器群,云服务厂商通过对外租赁服务器的形式代替了互联网厂商自己维护服务器的方式。这样做的好处在于一是避免了闲置基础设施资源的浪费,二是随着云服务的不断普及,以及Agile,DevOps运动的兴起,人们对IT设施的灵活度要求越来越高,这两年Infrastructure as Code(基础设施即代码)的理念已经被越来越多的厂商应用到生产实践中去,基础设施及代码的理念,和云服务是一脉相承的,租户可以更快地申请到设备,可以更灵活的对自己的设备定制化,规定大小,容量,甚至预配置一些环境,和自己的服务紧耦合,使公司的生产活动可以跟多的关注在业务上,而不用去操心服务器的性能,预估自己能承受的访问量,从而给业务发展带来更大的发展空间。这一点表现在今年AWS大力在推行的的Serverless架构上。
在笔者看来,云服务并不是一个技术上的创新,而更像是一种商业模式,为了让企业更灵活的适应瞬息万变的市场和用户需求,为了使社会资源更加合理化配置,同时,云服务也是信息全球化的重要一环,为人工智能,大数据奠定了基础。
如何定义一个良好的架构
AWS从五大支柱来判定一个架构设计得是否优秀:
- Security安全:保护信息,系统安全,在风险可控的前提下对外提供服务,以及迁移的策略
- Reliability可靠:系统的容错能力和自我修复能力,系统在负载增加时动态获取计算资源以满足业务需求,以及在系统模块发生故障时自动替换掉故障模块
- Performance Efficiency负载能力:根据系统需要,伸缩负载的能力
- Cost Optimization资费优化:在满足需求的情况下花尽可能少的钱
- Operational Excellence运维出色:业务连续性,系统状况监控预警能力
一般设计原则(General Design Principles)
- 停止估算需要多少基础设施,架构可以根据业务情况灵活伸缩
- 构建一个和生产环境完全一致的测试环境,你可以在测试环境完全模拟生产环境的情形,并在完成测试之后清理掉所有资源
- 自动化使架构变更的风险更低,基础设施及代码的好处,让架构可复制,架构变更变得可追踪,且减少了很多情况认为操作带来的风险
- 允许架构更灵活地变更,一是风险更低,因为变更可追溯,二是架构可以被及时回滚,三是彻底的变更成本很小
- 数据驱动型架构,灵活的架构方式允许你使用面向数居的架构方式
- 通过“game day”来提升架构,由于架构可以被轻易的复制且用户只需要按使用付费,租户可以在任意时候测试自己的架构是否存在安全漏洞,是否存在可以被改进的地方
下面白皮书围绕以上提到的几大优秀架构的设计支柱,提出了一系列设计原则,最佳实践以及实践这些最佳实践可以用到的服务:
安全(Security Pillar)
设计原则
- 在每一个层面引入安全:除了应用安全还应该在网络,负载均衡器,防火墙,操作系统关注安全
- 可追溯:保证系统的每一次操作/更改都被记录日志,并对日志进行审查
- 确保“最小权限原则”:确保每一个资源都被赋予了恰好需要的最小权限,实时审查这些权限,及时清理掉没用的权限
- 关注在你的系统安全:根据AWS的责任划分模型,关注在用户应该负责的系统安全和数据安全层面
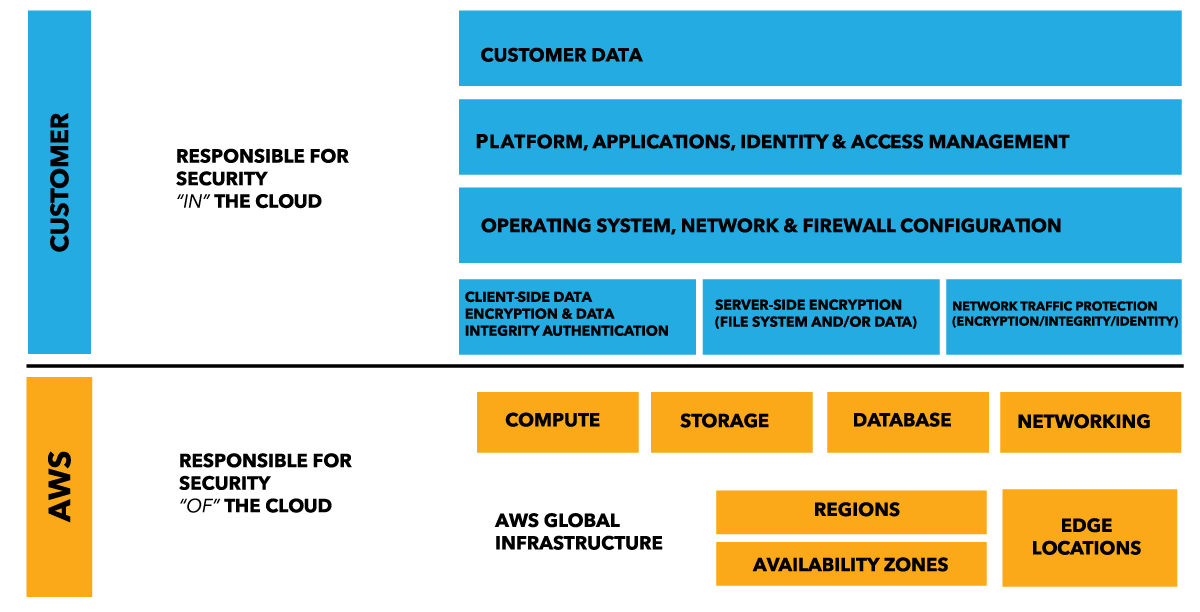
- 自动化安全最佳实践:使用基于应用层的策略保证安全问题能够被快速修复,例如,创建打好补丁的镜像,然后让所有之后创建的instance使用这个镜像;再例如,对常见安全问题自动响应和自动修复故障
定义
AWS将最佳实践划分为五个范畴:
- 数据保护
- 认证和权限管理
- 架构保护
- 追踪控制
- 事件响应
在设计你的架构之前,你需要知道谁可以对你的系统做什么,此外,你还希望确定判断每个发生在系统的事件是否安全,保护你的操作系统和服务,你需要维护和保密你的数据,你还需要做到系统对安全事件能够自动响应。
最佳实践
数据保护
确认只有必要的用户有访问部分数据的权限,确保数据在存储时被加密,传输过程中被加密,使用IAM,以下实践可以保证你的数据安全:
- AWS的用户享有对所有数据完全的控制权
- AWS确保用户可以轻松对自己的数据进行加密,并提供方法管理加密所使用的key,并可以通过AWS或者用户自己定义的方式自动定期更换key(Key Management Service)
- AWS允许开启详细的日志信息,包括文件的权限变更(CloudTrail)
- AWS提供极高的可用性保证你的数据不会丢失(S3)
- 开启版本管理,可以作为数据生命周期的一部分,可以保护对数据的误操作
- AWS默认不会对数据做跨Region的转移或备份,即数据不会离开它所在Region的“国家/城市”
另外两个重要的问题:
- 如何保证数据存储时加密?
- 如何确保数据传输过程的加密?(SSL)
认证和权限管理
通过亚马逊的AMI,租户可以完全控制根账户下每个用户,以及应用对所有资源的访问权限,确保每个User和Role只拥有必须的权限是必要的,同时确保每个资源只在被授权的情况下才能够被访问和使用。常见的权限管理包含以下内容:
- ACL(用于管理用户对于S3中存放对象的操作访问权限)
- 基于Role的权限控制
- 密码管理(定期更换密码)
同样,几个问题:
- 如何保证根账户的安全?(是否开启了第三方验证,是否删掉了Access Key)
- 如何保证User和Role的权限是安全的?(是否使用Group管理用户)
- 如何限制应用程序,脚本,或第三方工具对AWS资源的控制访问权限?
- 如何管理Key和证书?
架构保护
通常来说架构保护指的是对本地数据中心的保护,在AWS的白皮书中主要提到的是对于VPC的保护,主要包括VPC中的Security Group,Network Control list,路由策略
几个问题:
- 如何管理你的网络策略,和设备安全?(是否有内外网划分,在外网的Instance的登录验证是怎样的,有没有开启多重验证)
- 服务层面的安全管理?(多少用户有对你资源的访问权限,是否有对这些用户进行分组管理,是否对这些用户的验证进行了强行的限制,如强密码和定期更换密码,等等)
- 如何保证你的系统安全,如何运维监控你的服务?
追踪控制
以下服务可以用于设施变更的追溯及审查:
- CloudTrail,用于记录AWS API的每一次操作,并生成日志保存在S3中
- Amazon CloudWatch,用于实时监控和预警
- AWS Config
- Amazon S3
- Amazon Glacier
常见问题:
- 如何获取和分析你的日志?
涉及到的服务(Key AWS Services)
- 数据保护:加密数据存储和传输:ELB, S3 & RDS
- 权限管理:IAM, MFA
- 架构保护:VPC, NCL, SG
- 追踪控制:CloudTrail, Config, CloudWatch
可靠性(Reliability Pillar)
设计原则
- 测试覆盖率
- 自动修复错误
- 水平扩展
- 停止猜测生产力
- 自动追踪架构变更
最佳实践
建立基础
在开始架构设计之前,选择Region,确立方案。
- 如何管理AWS对服务数量的限制
- 如何设计网络拓扑
- 是否有预留空间用于处理技术难题
变更管理
这里说的变更主要指的是架构的水平扩展
- 如何根据业务需求进行系统变更
- 如何监控变更
- 如何执行变更(自动化)
容错管理
- 数据备份
- 灾难恢复
- 如何应对应用组件失效
- 如何对系统弹性进行测试
涉及到的服务
- 建立基础:IAM, VPC
- 变更管理:CloudTrail
- 容错管理:CloudFormation
性能负载(Performance Efficiency Pillar)
这一个支柱的核心思想是如何使用变更的计算资源来满足日益变化的业务需求
设计原则
- 为用户隐藏更多的细节让用户可以轻松调度资源,更关注在产品的业务价值
- 数分钟内让服务发布到全球
- 使用无服务(Serverless)架构
- 更容易实验
- 使用最符合用户想要实现的技术方法。例如,在选择数据库或存储方法时考虑数据访问模式。
最佳实践
选择
- 架构:数据驱动/事件驱动/ETL(数据仓储)/Pipeline,架构的选择决定了以下几种资源的选择
- 计算:Instance(type, monitor, quantity )/Container/Function,同时要考虑到水平扩展能力
- 存储:涉及到存储服务选择(S3/S3 IA/S3 RRS/Glacier),存储介质选择(SSD/HDD)
- 存储方式:块存储、文件存储、对象存储
- 访问方式:随机还是连续
- 吞吐量要求
- 访问频率:在线、离线、存档
- 更新频率:缓慢变更、动态实时更新
- 可用性限制
- 数据耐久度限制
- 数据库:RDS/DynamoDB/Redshift
- 网络:考虑地址,网络延迟(是否需要PlacementGroup),在各服务组合方式中寻找合适的配置Cloudfront, VPC, DirectConnect, Route53
回顾审视
设计好一个架构,应该再次审视你的架构是如何配合业务需求的,以及随着业务的改变,当引入新的资源类型和功能时,如何确保继续拥有最合适的资源配置?
监控
如何监控服务器负载和性能
时间空间的平衡
如何用增加空间,冗余备份的方式提高系统响应速度,增加性能负载。最明显的例子就是利用Cloudfront将静态文件缓存到各个节点从而增加各个地区的访问速度
涉及到的服务
- 选择
- 计算:Auto Scaling是关键,确保你拥有合适数量的Instance来满足业务需求
- 存储:EBS提供灵活多样的存储介质及参数,比如SSD, PIOPS,S3提供了静态文件交付方式,Amazon S3 Transfer Acceleration使用户可以远距离,快速,方便,安全的传输大文件
- 数据库: RDS(IOPS,Read Replicas)DynamoDB可以灵活扩展且提供毫秒级延迟的服务
- 网络:Route53可以提供根据地区延迟分发的路由策略,VPC endpoint(NAT, VPN, Direct Connect)开启灵活的网络互连
- 回顾审视:AWS Blog和AWS What’s New section可以看到AWS又推出了何种新服务
- 监控:AWS CloudWatch提供了不同维度(Metrics)的监控,触发事件(alarms),以及提示(Notifications),可以配合Lambda对监控事件作出反应
- 空间换时间:AWS ElastiCache,Cloudfront,Snowball,以及RDS的Read Replicas都是为了空间换时间的典型
费用优化(Cost Optimization Pillar)
设计原则
- 采用消费模式:根据使用情况实时变更资源配置,而不是精确估计资源使用情况
- 收益与经济规模:因为AWS拥有比单个企业大得多的经济规模,可以在各个企业的需求之间平衡资源需求,所以价格将会更加便宜
- 停止在自建数据中心中的投入
- 分析支出:云使得资源利用率和成本更加透明,有助于企业主衡量投资回报率,并为用户提供优化资源降低成本的机会
- 托管服务降低成本
最佳实践
- 更佳有效地利用资源
- 更贴近业务需求
- 支出意识:
- 清楚地认识到哪些服务是会被收费的,收费方式怎样,哪些服务是免费的
- 监控支出
- 及时关闭不被使用的资源
- 给资源配置权限管理以控制花费
- 随时优化
涉及到的服务
- 有效利用资源:对于EC2,申请预留实例以减少开销,使用 AWS Trusted Advisor 找到可以减少花费的方式
- 贴近业务需求:Auto Scaling
- 支出意识:CloudWatch用于监控花费情况,SNS用于提示超出预算的花费
- 随时优化:AWS Blog和AWS What’s New section以及 AWS Trusted Advisor
运维出色(Operational Excellence Pillar)
运维出色应该是AWS配合DevOps运动推出的一系列实践:
设计原则
- 使用代码执行运维操作:运维的一个发展趋势是越来越自动化,比如我们可以用自动配置管理工具配置更改环境,响应实践等
- 强调配合业务需求的运维:将运营流程与业务目标相一致,减少不必要的运维指标
- 定期,小步,增量式的运维:工作负载应设计为允许组件定期更新,运维的更新也应该小步前进,且容易被回滚,在维护和更换组件时不应造成宕机时间
- 启用测试以对运维的误操作及时响应:对于组件更替和运维的操作应该有测试,及时发现变更错误以便于修复或回滚
- 在错误中学习:定期回顾对运维事件的处理方法以改进,持续推动卓越运维
- 保持操作流程:团队之间相互学习,及时更新文档,保证团队运维操作有统一流程,统一的运维方式
最佳实践
- 准备:何种最佳实践?选用何种配置管理?
- 开始作业:如何小步前进,如何监控每一次运维操作?
- 响应:如何对计划之外的运维操作做出响应?
涉及到的服务
- 准备:AWS Config,AWS Service Catalog,使用Auto Scaling和SQS来保证运维的连续性
- 作业:这一部分主要是CI/CD: AWS CodeCommit, AWS CodeDeploy, and AWS CodePipeline
- 响应:CloudWatch alarm
FAQ
可以看到AWS对于优秀网站的设计,除了一般要求的可靠,省钱,还根据云服务的基础设施可灵活变更的特点强调了水平扩展和架构灵活变更,以更好地满足业务需要,保证业务连续性(business continuity)
白皮书最后还给出了FAQ(Frequently asked questions)部分回答了一些关于最佳实践的常见问题,非常值得一看。