PaaS 平台(二) -- Kubernetes 介绍
Kubernetes 的很多概念和架构“代表了谷歌过去十余年设计、构建和管理大规模容器集群经验”。
Kubernetes 概念引入
Kubernetes 基于容器引入了许多重要的概念,了解这些概念有助于认知 Kubernetes 是如何工作的。
以下介绍均为 Kubernetes 中被定义的资源,Kubernetes 架构按照 Restful 架构设计,即遵循:
- 网络上的所有事物都被抽象为资源
- 每个资源对应一个唯一的资源标识符
- 通过通用的连接器接口对资源进行操作
- 对资源的各种操作不会改变资源标识符
- 所有操作都是无状态的
- REST是基于HTTP的
PS:REST之所以可以提高系统的可伸缩性,就是因为他要求所有的操作都是无状态的。
Pod

名词释义
Pod 意为豆荚,内涵多个共享网络和存储的容器,作为被Replication Controller, Label, Service操作的逻辑对象,是Kubernetes里能被创建、调度和管理的最小部署单元。可以想象成一个用于装 Container 的篮子:
- 一个 Pod 里能装多少资源取决于篮子的大小
- Label 是贴在篮子上的
- IP 分配给篮子而不是容器,篮子里的所有容器共享这个 IP
- 哪怕只有一个容器,Kubernetes仍然会给它分配一个 Pod,Pod里的Container数量也可以为零
- Pod 的运行状态:Pending、Running、Succeeded、Failed
Pod中的容器共享了IP及其对应的namespace, Volume;从 Linux 的 namespace 的角度看,Pod 里的容器还共享了 PID, IPC(信号量、消息队列、共享内存),UTS(主机名与域名) namespace
Pod 是为了解决“如何合理使用容器支撑企业级复杂应用”的问题而诞生的,Kubernetes 的设计理念是为了支持绝大多数应用的原生形态,而不是大谈特谈“轻应用”和“十二要素应用”;Pod 对于 Kubernetes 来说最有用的价值就是“原子化调度”,即在为一个 Pod 选择目的宿主机时,Kubernetes 会先考量这个机器是否能放下整个 Pod,而避免出现本应该部署在一起的容器因为资源不足无法满足“超亲密关系”的尴尬。
Pod 里面包含一个网络容器先于其他所有容器创建,拥有该 Pod 的 namespace。
用户可以使用 rsh 命令登录到一个 Pod 里,原理是在 Pod 里创建了一个 bash Container。
Pod 是如何被定义的
我们来看 Openshift 的一个 template 是如何描述一个 Pod 对象的:
# Kuberntes 是按照 Restful 标准设计,所以你能在每个资源对象中看到 API Version
apiVersion: v1
# 申明一个 Pod 类型
kind: Pod
metadata:
# 具有严格命名规范的注释,包含版本号,资源url,团队名等
annotations: { ... }
# 每个 Pod 需绑定一个或多个 Tag,方便 Replication Controller 和 Service 对 Pod 进行调度和管理
labels:
deployment: docker-registry-1
deploymentconfig: docker-registry
docker-registry: default
generateName: docker-registry-1-
spec:
# 下面是对 Pod 中 Container 的定义,Containers 为一个列表,可以配置不同类型的多个 Contianer
containers:
# Container 中被注入的环境变量
- env:
- name: OPENSHIFT_CA_DATA
value: ...
- name: OPENSHIFT_CERT_DATA
value: ...
- name: OPENSHIFT_INSECURE
value: "false"
- name: OPENSHIFT_KEY_DATA
value: ...
- name: OPENSHIFT_MASTER
value: https://master.example.com:8443
# Container 由哪个 image 启动
image: openshift/origin-docker-registry:v0.6.2
imagePullPolicy: IfNotPresent
name: registry
ports:
# 决定了 Pod 暴露出来的端口
- containerPort: 5000
protocol: TCP
resources: {}
securityContext: { ... }
# 决定了将被挂载到 Pod 里的外部存储设备挂载到 Container 的哪一个路径
volumeMounts:
- mountPath: /registry
name: registry-storage
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-br6yz
readOnly: true
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: default-dockercfg-at06w
restartPolicy: Always
serviceAccount: default
# 将外部存储设备挂在到 Pod 中,此处为一个临时存储,和一个加密存储
volumes:
- emptyDir: {}
name: registry-storage
- name: default-token-br6yz
secret:
secretName: default-token-br6yz
关于 Volume
Volume 是 Pod 中能被多个容器访问的共享目录,生命周期和 Pod 相同,如果有数据持久化考虑,如数据库的数据 Volume,通常需要调用云基础设施的持久化存储服务,如 AWS 的 EBS,EFS 等。
- EmptyDir: 在 Pod 被分配到 Node 时创建,初始内容为空,Pod 被移除时 EmptyDir 中的数据也会永久删除;常用于临时共享目录
- hostPath: 在 Pod 上挂载宿主机上的文件或目录;使用时要注意 Pod 会在不同 Node 上漂移的问题,可以用在比如 Redis 集群的数据卷
- NFS
- EBS 创建一个 EBS Volume,直接挂载到 Pod 里
- gitRepo: 挂载一个空目录,并下载一个 git repository
- …
关于 Label 和 Label Selector
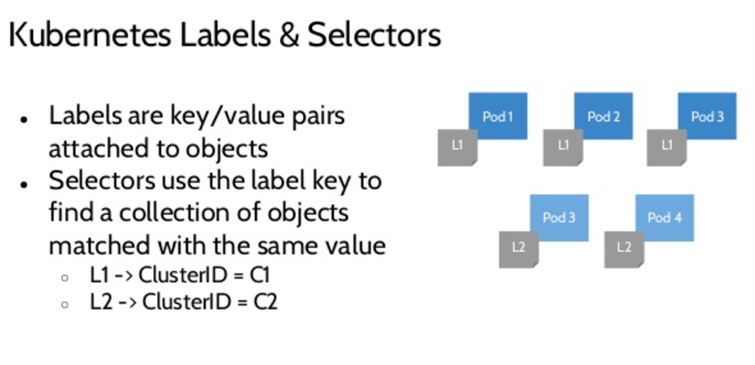
Label:Replication Controller 和 Service 通过 Label 对 Pod 进行选择和调度,Kubernetes 引入 Label 主要是为了面向用户,包含对象功能性和特征性描述的 Label 比对象名和 UUID 更加用户友好和有意义,而且使用户可以以一种松耦合的方式实现自身组织结构到系统对象之间的映射,无需客户端存储这些映射关系。
Label Selector:是 Kubernetes 核心的分组机制,用于让客户端识别一组有共同特征或属性的 Kubernetes 对象,这一特性促进了扁平化、多维度的服务组织和部署架构,这对集群管理(譬如配置和部署)和应用的自我检查分析(日志监控预警分析)非常有用。Label Selector 除了严格匹配还支持类似于 SQL WHERE 语句的查询。
Replication Controller

名词释义
Replication Controller 的作用是决定一个Pod在运行时同时有多少个副本,类似于 AWS 的 Auto Scaling Group,方法是在每一个 Pod 外挂了一个控制器进程,与 Pod 相互独立,避免造成性能瓶颈或挂掉影响 Pod。
Replication Controller 是 Kubernetes 为了解决“如何构造完全同质的 Pod 副本”的问题而引入的资源对象。其配置文件由三部分组成:一个用于创建 Pod 的 template,一个期望的副本数,和一个用于选择被控制的 Pod 集合的 Label Selector。Replication Controller 会不断地监测控制的 Pod 集合数量并与期望的副本数量进行比较,根据实际情况进行创建和删除 Pod 操作。
功能:弹性伸缩,灰度发布(需要两个 Replication Controller )。
Replication Controller 是如何被定义的
同样我们来看一个 Replication Controller 的配置文件:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend-1
spec:
# 描述这个 rc 中期望的同质 Container 的数量
replicas: 1
# Label Selecter 用于匹配期望的 Pod,以及给新创建的 Pod 打上标签
selector:
name: frontend
# 模板,用于定义 Pod
template:
metadata:
labels:
name: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always
Service
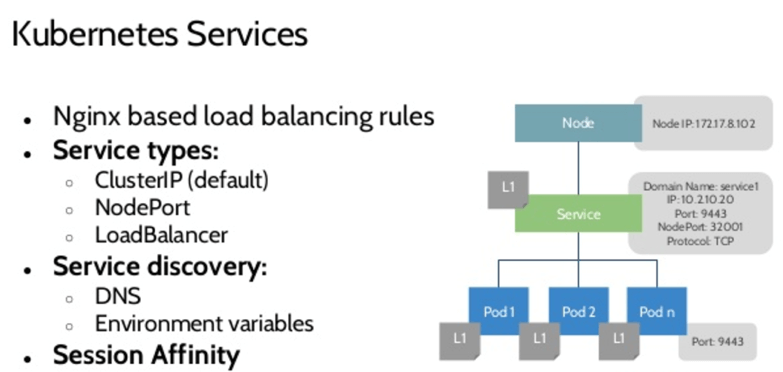
名词释义
由于重新调度等原因,Pod 在 Kubernetes 里的 IP 并不是固定的,因此需要一个代理来确保需要使用 Pod 的应用不需要知道 Pod 的真实 IP 地址,同时 Service 还为多个 Pod 副本提供负载均衡,可以类比 AWS 中的 ELB。
Service 由两部分构成,一个与 Service 生命周期相同的 IP 地址,和一个 Label selector;另外还需要配置转发端口 ,Service 对象创建后系统会创建一个同名 Endpoints 对象用于保存匹配 Label selector 后端 Pod 的 IP 地址和端口。
Service 可以置空 Label selector 用于代理非 Pod,或得不到 Label 资源的(遗留)系统。方法:通过在 Service 里定义端口转发,再在 Endpoints 中自定义IP和端口。
Service 提供外部访问服务有三种形式,利用 Kubernetest 集群 IP 池(由 Administrator 配置);利用宿主机(Node)的 IP 和端口;利用 LoadBalancer(如 AWS 的 ELB)。
另外,Service 是支持黏滞会话的。
Service 是如何被定义的
来看一个 Service 的配置文件:
apiVersion: v1
kind: Service
metadata:
name: docker-registry
spec:
# Label Selector
selector:
docker-registry: default
# Endpoint,可以用于代理内部/外部资源(需使用 ”ExternalIPs“)
portalIP: 172.30.136.123
ports:
- nodePort: 0
port: 5000
protocol: TCP
targetPort: 5000
Service Proxy
Service Proxy(Kube-proxy)负责在 Service 建立的时候在宿主机上随机监听端口并建立 Iptable 规则进行转发,同时 Kube-proxy 还会实时监测 Kubernetes 的 Master 节点上的 etcd 中 Service 和 Endpoints 对象的增加和删除信息,从而保证和后端 Pod 的 IP 和端口变化保持一致更新。
Service discovering:环境变量( Pod 创建时被注入所有可用 Service 环境变量形如 XXX_SERVICE_HOST=10.0.0.1)或通过 DNS(skyDNS服务器),调用 Kubernetes 的 WatchAPI, 不间断地监测新 Service 的创建并未每个 Service 新建一个 DNS 记录,在整个集群范围可用,在同 namespace 下的 Service 通过二级域名(Myservice)访问该 Service, 不同 namespace 下则可通过 my service.mynamespace 的方式访问到。DNS 的方式因为存在 TTL 导致服务 DNS 记录更新不及时而存在争议。
对于一部分要求外网可访问的 Service,可以通过 createExternalLoadBalancer=true(利用IaaS平台)或者维护一个 PublicIPs 池,利用 Kube-proxy 转发的方式实现。
健康检查
既然 Service 可以路由,必然也有对 Pod 进行健康检查的功能:
- 进程级别由 Kubelete 通过 Docker daemon 获取所有 Docker 进程的运行状态,如果某容器进程未正常运行则重启。
- 应用级别由Kubelete在容器内执行活性探针(liveness probe),支持 HTTP get, Container exec, TCP Socket 三种检查方式,默认情况确认失败会删除 Pod, 另外还有一个可选项是 readiness probe,即仅移除 Endpoint,这样保留Pod可以用于错误重现。
Pod + RC + Service
上面提到的 Pod,Replication Controller,Service 三种资源构成了 Kubernetes 集群中最常见的一种应用架构,如下图所示。
这个架构是不是很熟悉?没错,他和 AWS 里 Instance + Autoscaling Group + ELB 的架构是样的,如果你你对 AWS 的服务熟悉的话,可以据此来理解应用在 Kubernetes 里的架构:
- Pods - Instances
- Replication Controllers - Auto Scaling
- Services - Elastic Load Balancing
- Nodes - Availability Zone
Kubernetes 架构
Kubernetes 的架构如下图所示,对于学习 Openshift 这部分内容仅作兴趣了解即可,PaaS 平台的存在就是为了屏蔽掉这些底层细节。
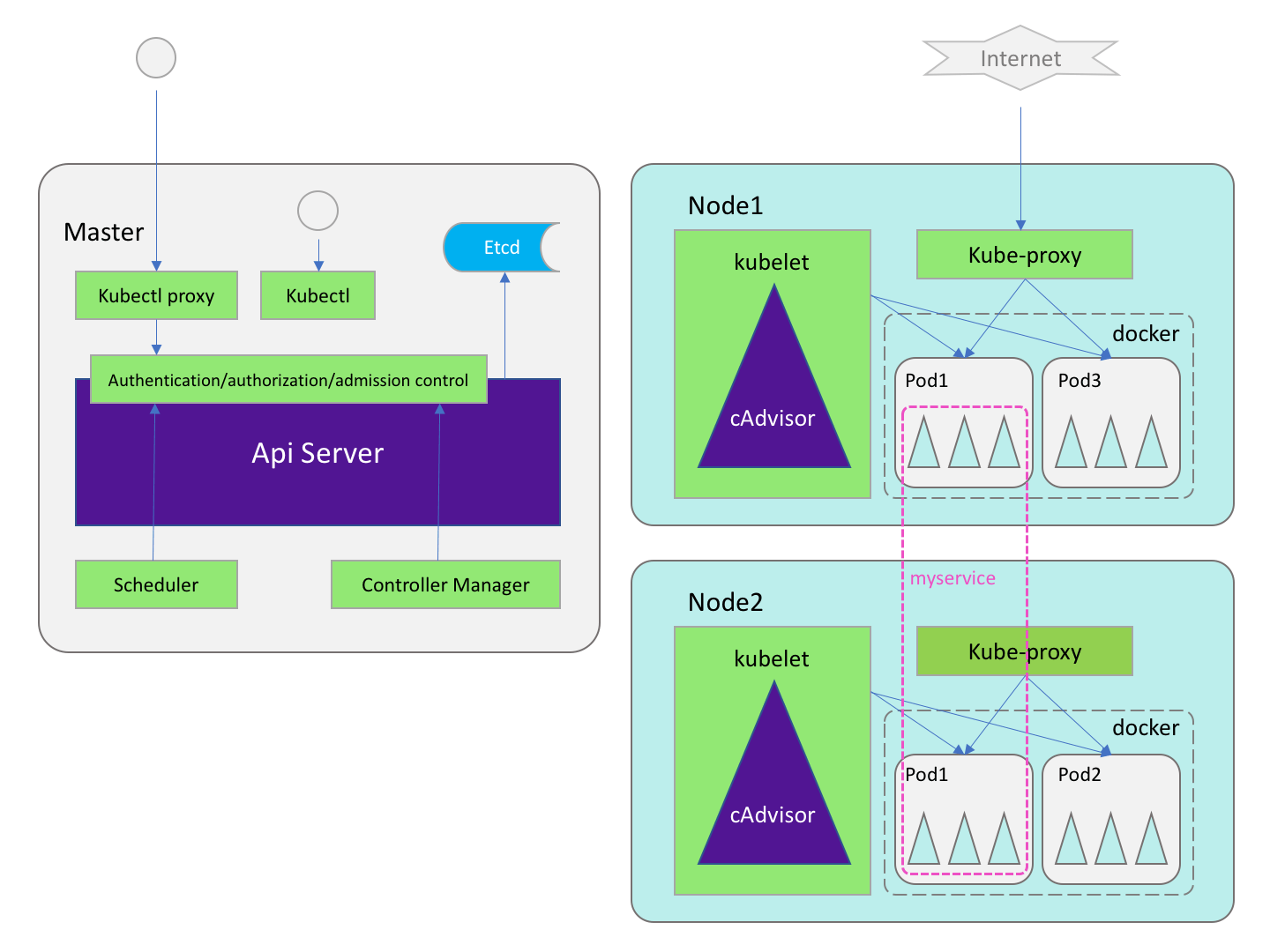
APIServer:
运行在 Master 节点,对外作为系统管理指令的统一入口,任何对资源进行的增删改查都要交给 APIServer 处理后才能提交给 etcd。(etcd 是一个键值对数据库,是 APIServer 的唯一持久化节点)
API Server 分为只读端口(Kubernetes-ro service, port:7080)和读写端口(Kubernetes service port:6443),基于 etcd 实现了一整套 RESTful API 用于操作存储在 etcd 中的 Kubernetes 对象实例,APIServer 借助一个被称为 registry 的实体来完成对etcd的所有操作。
Scheduler
根据特定的调度算法将 pod 调度到指定的 Node(早期也被叫做minion) 上,也叫绑定。
工作节点描述方式:期望状态(由 Json 描述),当前状态,包括:HostIP,Node Phase(Pending, Running, Terminated), Node Condition(NodeReady),由 controller manager 下属的 node controller 循环检查 Node 中的 minion 进程获得。
调度算法:Predicates(能不能-端口是否冲突、资源是否够用、Volume 是否有冲突、NodeSelector 是否选中(label selector的一种)、HostName 指定 Node); Priorities(资源占用比小、Pod数量少、平等对待每个 Node (默认情况不使用))
Controller manager
运行在 master 上的一个基于 Pod API 的独立服务,重点实现了 service endpoint 的动态更新,管理 kubernetes 集群中的各种控制器(replication controller, node controller,..),用于确保资源保持在预期状态。
- Replication controller:每五秒执行一次检查,将返回的健康pod数量和描述文件中定义的数量做个 diff,再根据结果调用 APIServer 执行新建或删除
- Service endpoint controller: 每十秒执行一次检查,遍历集群中所有 namespace 下 service 对象,取到 service 的 label selector 获取 service 对应的后端 Pod 对象列表,将 Pod 和 Service 的详细信息以 Pod 为单位封装成一个个 Endpoint 对象,这就是实际的 Endpoint 对象;用于和 APIService 在 etcd 中检索到的 Endpoint 期望状态进行比较, 在根据 etcd 中的期望调用 APIServer 创建或销毁资源。
- Node controller: 判断是否工作在 IaaS 上,是则直接掉 IaaS API 获取所有可工作节点;定期向 APIServer 注册以此工作节点;每隔五秒 pull 一次 Node 中 kubelet 发送过来的工作节点运行状态,retry 超过30秒无响应设置 node 状态为 Unknow,然后,调用 APIServer 更新 etcd 中的节点信息,如果时间超过 PodTvictionTimeout,则在 etcd 中删除所有 Pod 对象。
- Resource quota controller: 用于追踪集群资源配额的实际使用量,期望值由管理员静态设置。
Kubelet
Kubelet 是运行在 Kubernetes 集群中子节点上的进程,负责管理和维护 Node 上的所有容器。Kubelete 利用 Dokcer cAdvisor 进程用于监控 Node 的状态并将数据汇报给 master。
垃圾回收: 容器回收(goroutine 每一分钟调用 Docker 客户端过滤出停止且超过 MinAge 的容器以 Pod 为单位放到 EvictUnit 中,判断宿主机允许回收,则删除)。
镜像回收(每五分钟遍历一次,筛选出最长时间没有被使用且大于指定时间的 Image 删除)
同步工作节点。
Kube-proxy
Kube-proxy 既支持 HTTP,也支持 TCP 和 UDP 连接,默认情况下提供 Round Robin 算法将客户端流量复杂均衡到 Service 对应的一组后端 Pod,最重要的是 Kube-proxy 还支持 Session Affinity(Session Sticky,会话黏滞)。而服务发现上,Kube-proxy 使用 etcd 的 Watch 机制,监控集群 Service 和 Endpoint 对象数据的动态变化,并且维护一个从 Service 到 Endpoint 的映射关系,从而保证了后端 Pod 的 IP 变化不会对访问者造成影响。
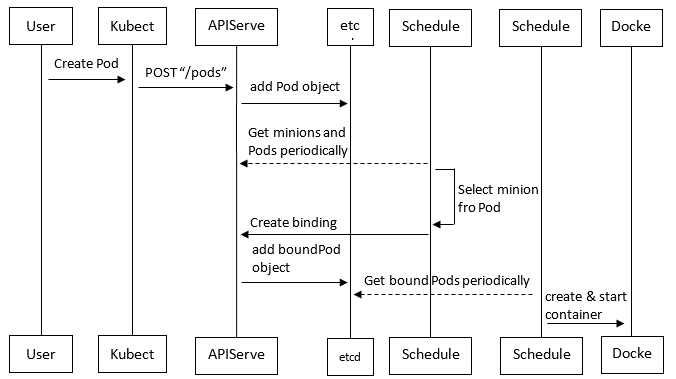
核心组件协作流程
费心巴力在网上找了描述准确的图但是他每个对象都少了最后一个字母,更正如下,从左到右:
Kubectl APIServer etcd Scheduler Kubelet Docker
- 参考资料:
- 《Dokcer 容器与容器云》浙江大学 SEL 实验室著
- 《Kubernetes权威指南》龚正,吴治辉,王伟 等著
- https://www.slideshare.net/imesh/revolutionizing-wso2-paas-with-kubernetes-app-factory
- https://docs.openshift.org/latest/architecture/core_concepts/index.html
- https://kubernetesbyexample.com/
- https://kubernetes.io/docs/concepts/