领域驱动设计(DDD)实践
DDD(Domain Driven Design, 领域驱动设计)是一套原则、约束和方法。广义上的 DDD 是为了解决解决跨部门间语言沟通问题,在业务、产品、开发之间建立领域通用语言(Ubiquitous Language)以提高沟通效率。落地到开发团队,DDD 可以指导我们进行架构设计、团队划分、拆分微服务、乃至代码层面的设计。主要解决系统无法随业务演变而演变的问题。
DDD 的战术设计体现:
// Bad
List<Item> items = order.getItems();
items.remove(item);
// Good
order.removeItem(item);
为什么要 DDD
传统的设计模式中,不管是 MVC,MVP,还是 MVVM 本质上都是数据驱动的。核心上基于M推送消息,V或P来订阅 这个模型。使用者需要维护的不再是 UI 树,而是抽象的数据。(通过数据,可以随时构建出新的 UI 树) ,这种设计在短时间内可以灵活地应对 UI 的变化,但是对于更为复杂的业务变化(比如数据结构的变化),就需要在各个模块都进行修改,修改的内容分散、影响面广、风险大,长此以往,原本架构清晰的系统随着迭代的不断演化,业务逻辑变得越来越复杂,我们的系统也越来越冗杂。模块彼此关联,谁都很难说清模块的具体功能意图是啥。修改一个功能时,往往光回溯该功能需要的修改点就需要很长时间,更别提修改带来的不可预知的影响面。

之所以产生这种现象,归根到底在于随着业务的变化系统架构变得不清晰,划分出来的模块内聚度低、高耦合。理想情况下,如果我们的代码逻辑按照业务结构来组织,代码架构就可以随着业务的变化变化,这样代码就会变得易于维护;由于要去阅读代码的人首先需要具备领域知识,代码又是对业务的直接呈现,代码的可读性也会极大提高。
任何一种理念的落地都不是一蹴而就的,我下面从战术设计和代码实践的角度,围绕一个案例探讨一下 DDD 的几个核心概念。
六边形架构(Hexagonal Architecture)
六边形架构(Hexagonal Architecture),又称为端口和适配器风格,最早由Alistair Cockburn提出。在DDD社区得到了发展和推广,之所以是六变形是为了突显这是个扁平的架构,每个边界的权重是相等的。
我们知道,经典分层架构分为三层(展现层、应用层、数据访问层),而对于六边形架构,可以分成另外的三层:
- 领域层(Domain Layer):最里面,纯粹的核心业务逻辑,一般不包含任何技术实现或引用。
- 端口层(Ports Layer):领域层之外,负责接收与用例相关的所有请求,这些请求负责在领域层中协调工作。端口层在端口内部作为领域层的边界,在端口外部则扮演了外部实体的角色。
- 适配器层(Adapters Layer):端口层之外,负责以某种格式接收输入、及产生输出。比如,对于 HTTP 用户请求,适配器会将转换为对领域层的调用,并将领域层传回的响应进行封送,通过 HTTP 传回调用客户端。在适配器层不存在领域逻辑,它的唯一职责就是在外部世界与领域层之间进行技术性的转换。适配器能够与端口的某个协议相关联并使用该端口,多个适配器可以使用同一个端口,在切换到某种新的用户界面时,可以让新界面与老界面同时使用相同的端口。
这样做的好处是将使业务边界更加清晰,从而获得更好的扩展性,除此之外,业务复杂度和技术复杂度分离,是 DDD 的重要基础,核心的领域层可以专注在业务逻辑而不用理会技术依赖,外部接口在被消费者调用的时候也不用去关心业务内部是如何实现。
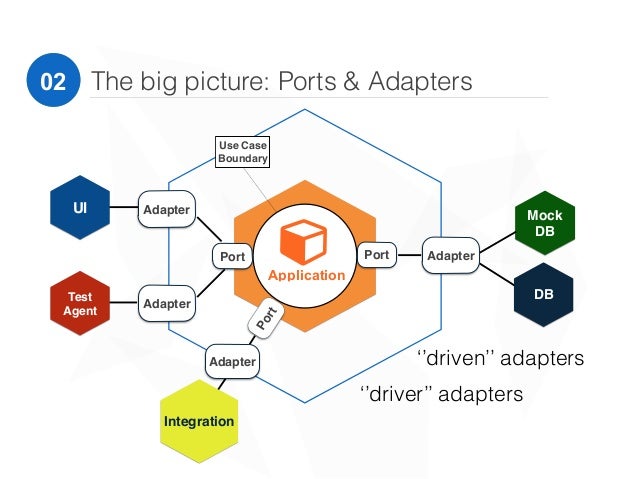
正如上文提到,六边形架构的出现早于 DDD,要实现 DDD 也不是非要采用六边形架构,只是这种架构正好契合了 DDD 所需的条件,从六边形架构出发,可以更容易理解 DDD 的思想。如上图所示, Adapter 所在的绿色线框表示限界上下文,中间橙色的六边形表就是应用服务,标记出核心领域模型对外暴露的功能和方法。Application 所在的核心就是领域模型,包含领域对象和领域服务,其中领域对象又分为实体对象和值对象,值对象中的一个特定对象就是聚合根,聚合根就是这个领域的核心。
落实到代码层面,也可以用分层架构来理解,DDD 架构从上到下可以分为四层:
用户界面层(或表示层)
负责向用户显示信息和解释用户指令,这里指的用户可以是另一个系统,不一定是使用用户界面的人。应用层
定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。应用层要尽量简单,不包含业务规则或者知识,而只为下一层中的领域对象协调任务,分配工作,使他们相互协作,他没有反应业务情况的状态,但是却可以具有另一种状态,为用户或程序显示某个任务的进度。领域层(或模型层)
负责表达业务概念,业务状态信息以及业务规则。尽管保存业务状态的技术细节是由基础设施层实现的,但是反应业务情况的状态是由本层控制并且使用的。领域层是业务软件的核心。基础设施层
为上面两层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制,等等。

限界上下文(Bounded Context)
限界上下文大部分情况下被划入战略设计的范畴,可以用于指导拆分代码库、部署单元、微服务甚至团队。
限界的意思是划定边界,边界内部的领域逻辑应该有尽可能少的交集;上下文的意思就是语境,即特定的对象在特定的语境下的模型是不同的,例如轮胎这个对象在修理汽车这个上下文中,其模型只需要包含品牌、型号两种属性,而在出售汽车轮胎的上下文中的模型还应该包含制造厂商、价格的属性。
边界通过限界上下文来确定,这在领域驱动设计中具有非凡的意义。对应于通用语言,限界上下文是语言的边界,对于领域模型,限界上下文是模型的边界,二者对应于问题空间(Problem Space)的界定。对于系统的架构,限界上下文还确定了应用边界和技术边界,进而帮助我们确定整个系统及各个限界上下文的解决方案。可以说,限界上下文是连接问题空间与解决方案空间的重要桥梁。
应用服务(Application Service)
应用服务是用来表达用例和用户故事(User Story)的主要手段。
应用层通过应用服务接口来暴露系统的全部功能。在应用服务的实现中,它负责编排和转发,它将要实现的功能委托给一个或多个领域对象、领域服务、和资源库来实现,它本身只负责处理业务用例的执行顺序以及结果的拼装。
应用层相对来说是较“薄”的一层,除了定义应用服务之外,在该层我们可以进行安全认证,权限校验,持久化事务控制,或者向其他系统发生基于事件的消息通知。
应用层作为展现层与领域层的桥梁。展现层使用VO(视图模型)进行界面展示,与应用层通过DTO(数据传输对象)进行数据交互,从而达到展现层与DO(领域对象)解耦的目的。一个应用服务应该包含以下功能和特点:
- 处理基本数据类型
- 向外暴露业务能力
- 不包含业务逻辑
- 对应业务用例(非CRUD)
- 组织协调
- 事务边界
- 日志
- 一层而非一个对象
一个理想的 Service 应该包含四个动作:get、update、save,举个例子,用户初始化密码的一个事件:
public void initialPassword(SetPasswordCommand command) {
User user = userRepository.findByUuid(command.getUuid()).orElseThrow(UserNotExistException::new); // 获得 User
user.setPassWord(command.getPassword()); // 更新 User
logger.info("Set password with uuid[{}]", command.getUuid()); // 日志
userRepository.save(user); // 持久化 User
}
除了对领域对象的操作,ApplicationService 还会承担解构技术数据为业务数据(划分领域边界)、日志(反应业务状态)的功能。
有时候业务逻辑的处理会比较复杂,以创建用户为例,最好使用构造函数处理,但如果面临比较复杂的场景,比如还需要对用户输入的信息进行验证,就可以使用一个工厂类来创建我的领域对象,这个时候这个工厂类就是一个领域服务,所有核心业务逻辑都应该在领域服务中,而不要在 ApplicationService 层:
public String register(RegistrationCommand command) {
User user = registerService.createUser(command.getOwnerEmail(), command.getPolicyNumber()); // 调用 RegisterService 执行创建 User 的动作,业务相关验证也在 RegisterService 里面
logger.info("Create user with email [{}]", command.getOwnerEmail()); // 日志
return user.getUuid(); // 返回业务需要的 ID
}
领域模型(Domain Model)
领域模型是业务代码所在区域,也是服务的核心所在,领域模型分为领域对象和领域服务两大类,领域对象用于存储状态,领域服务用于改变领域对象的状态。
领域服务(Domain Service)
领域层就是较“胖”的一层,因为它实现了全部业务逻辑并且通过各种校验手段保证业务正确性。而什么是业务逻辑呢?业务流程、业务策略、业务规则、完整性约束等。
当领域中的某个操作过程或转换过程不是实体或值对象的职责时,我们便应该将该操作放在一个单独的接口中,即领域服务。请确保该服务和通用语言时一致的;并且保证它是无状态的。
领域服务无状态怎么理解?
领域服务是用来协调领域对象完成某个操作,用来处理业务逻辑的,它本身是一个行为,所以是无状态的。状态由领域对象(具有状态和行为)保存。
什么时候使用领域服务?
领域对象是具有状态和行为的。那就是说我们也可以在实体或值对象来处理业务逻辑。那我们该如何取舍呢?
一般来说,在下面的几种情况下,我们可以使用领域服务:
- 执行一个显著的业务操作过程
- 对领域对象进行转换
- 以多个领域对象为输入,返回一个值对象。
以用户登录为例,登录是一个显著的业务操作过程,因此把它作为一个领域服务,登录需要验证邮箱是否存在,如果存在则进行密码验证,这些属于核心业务逻辑,不应该暴露在ApplicationService 里面,所以 Application Service 里的 login 方法是这样:
public boolean login(UserLoginCommand command) {
boolean loginSuccess = loginService.login(command.getEmail(), command.getPassword());
logger.info("User login with email [{}]", command.getEmail());
return loginSuccess;
}
而表达业务含义的核心代码在领域服务 LoginService 里面:
@Service
public class LoginService {
@Autowired
UserRepository userRepository;
public boolean login(String email, String password) {
User user = userRepository.findByEmail(email).orElseThrow(UserNotExistException::new);
Boolean loginSuccess = user.isPassWordCorrect(password);
if(loginSuccess) user.online();
return loginSuccess;
}
}
可以看到领域服务并没有保存登录有关的状态,而是在 User 里记录了 Online,领域服务中也可以调用领域对象的方法完成一些验证、状态更新的操作。
需要注意的是,领域服务不用特别关心实现细节,只用写业务代码,以创建 Policy 的 PolicyFactoryService 的 createPolicy 为例:
public HomePolicy createPolicy(CreateHomePolicyCommand command) {
HomePolicy homePolicy = homePolicyMapper.map(command, HomePolicy.class);
if (!homePolicyQuotationRepository.existsByQuoteId(homePolicy.getQuoteId()))
throw new InvalidQuotationException();
homePolicyRepository.save(homePolicy);
return homePolicy;
}
homePolicy.map 是一个技术动作,就不宜出现在领域服务中,这里用构造方法代替会更好,map 这类数据类型转换的动作可以放到 ApplicationService 中。
领域对象(Domain Object)
领域对象有分为实体对象和值对象,实体对象是具有生命周期,有唯一标示,可以通过 ID 判断相等性,有增删改查操作,可记录状态的一些对象,比如 Policy,User。如下是一个”贫血的领域对象“,之所以说它是领域对象是因为它有唯一标示,之所以它贫血是因为它没有业务动作。
@Getter
@Setter
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@Table(name = "POLICY")
public class Policy {
@Id
private String policyNumber = UUID.randomUUID().toString();
private LocalDate startDate;
private String quoteId;
@Embedded
@AttributeOverrides(value = {
@AttributeOverride(name = "id", column = @Column(name = "policy_holder_id")),
@AttributeOverride(name = "name", column = @Column(name = "policy_holder_name")),
@AttributeOverride(name = "email", column = @Column(name = "policy_holder_email")),
@AttributeOverride(name = "birthDay", column = @Column(name = "policy_holder_birthday"))
})
private PolicyHolder policyHolder;
}
由于 Policy 只需要被创建,所以它并不包含改变自身状态的方法,但所有业务上对 Policy 会有的操作都已经包含在了这个领域对象中,所以它还是一个聚合根。
值对象是指起描述作用,无唯一标识,只能通过属性判断是否相等,即时创建,用完即回收的不可变对象,例如 Policy 的子属性 PolicyHolder:
@Getter
@Setter
@Embeddable
public class PolicyHolder {
private String id;
private String name;
private String email;
private LocalDate birthDay;
}
它只是作为 Policy 的一个成员类,不能有自己的动作,所有对 PolicyHolder 的操作必须通过聚合根 Policy 来进行,对于一个 Policy 而言,要换 PolicyHolder 的话要重新实例化一个 PolicyHolder,所以这个地方他只是个值对象,他的持久化依赖于聚合根 Policy。
// Bad
PolicyHolder oldHolder = Policy.getHolder();
oldHolder.update(newHolder);
// Good
Policy.updateHolder(newHolder);
现在你应该很清楚文章开头那里例子了吧,第二种实现屏蔽了 Policy 里的结构细节,我只需要知道我更新了 Holder 就可以,至于如何更新的并不需要关心。
聚合根(Aggregate Root)
在领域对象的部分已经谈到了聚合根,聚合根属于实体对象,它是领域对象中一个高度内聚的核心对象。一个领域内的数据一致性由聚合根保证,聚合根之间的数据一致性就要通过最终一致性来完成。
聚合根可以被应用服务直接调用,如在 initialPassword 方法中调用
user.setPassWord(command.getPassword());
或者领域对象的构造方法。
聚合根也可以在领域服务里被调用,如在 LoginServer里调用
user.isPassWordCorrect(password);
资源库(Repository)
理想情况下一个实体对象的生命周期开始于一个 Factory,终止于 Repository 。
资源库是生命周期的结束,它封装了基础设施以提供查询和持久化聚合的操作。这样能够让我们始终聚焦于模型,而把对象的存储和访问都委托给资源库来完成。需要注意的是,资源库并不是数据库的封装,而是领域层与基础设施之间的桥梁。DDD关心的是领域内的模型,而并非是数据库的操作。理想的资源库对客户(领域服务和应用服务)隐藏了内部的工作细节,委托基础设施层来干那些脏活,到关系型数据库、NOSQL、甚至内存里读取和存储数据。因此资源库有以下两个特性:
- 可插拔性
- 聚合根的集合
仓储的要点并不是使代码更容易测试,也不是为了便于切换底层的持久化存储方式。当然,在某种程度上,这也的确是仓储所带来的利好。仓储的要点是保持你的领域模型和技术持久化框架的独立性,这样你的领域模型可以隔离来自底层持久化技术的影响。如果没有仓储这一层,你的持久化基础设施可能会泄露到领域模型中,并影响领域模型完整性和最终一致性。
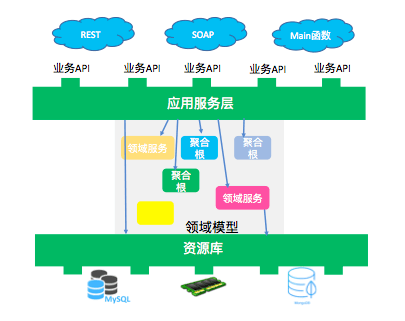
如图所示,应用服务层不必关心技术层返回使用何种标准,只作为领域模型对外暴露接口的服务。在领域模型中有领域服务、聚合根两种模块,业务操作通过领域服务改变聚合根状态实现,状态持久化通过资源库调用底层数据库实现,同样,资源库的调用者也不需要担心持久化的技术细节,需要何种数据库、如何进行存储,都交给 Repository 的内部实现来做。图中的箭头表示的是“领域事件”。
领域事件(Domain Event)
用例-应用服务-聚合根-事务
领域事件应该对应到聚合根上的一个操作,承担了记录业务活动、解耦限界上下文、保证最终一致性三个重要的责任;可以由应用服务或者资源库发布。他有两个重要的特性:幂等性和原子性:
- 幂等性:消费方接受多条 event 和接受一条是结果是一样的。这是由于以 MQ 为例,为了保证最终一致性往往会重复发送同一个事件,这个时候接受方就要进行处理,保证不会出现错误或是冗余的数据。
- 原子性:虽然在不同聚合根之间我们采用了基于领域事件的最终一致性,但是在业务操作和事件发布之间我们依然需要采用强一致性,也即这两者的发生应该是原子的,要么全部成功,要么全部失败,否则最终一致性根本无从谈起。
后记
DDD 是一种思想,采用 DDD 并不是要一次全盘接受他的所有实践,好的实践需要加以时间打磨,适合业务和团队的才是最好的。
文中提到的代码,完整版在这里:https://github.com/ADU-21/ddd_demo
- References:
- https://www.cnblogs.com/netfocus/archive/2011/10/10/2204949.html
- https://tech.meituan.com/DDD%20in%20practice.html
- https://insights.thoughtworks.cn/from-sandwich-to-hexagon/
- http://www.cnblogs.com/xishuai/p/iddd-soa-rest-and-hexagonal-architecture.html
- http://www.cnblogs.com/sheng-jie/p/7097129.html
- http://qinghua.github.io/ddd/